



¿Estás listo para impulsar tu negocio en el mundo digital? En HiveAgile, sabemos lo crucial que es estar bien conectado en el entorno digital actual. Por eso, estamos emocionados de presentarte nuestros nuevos planes de membresía, pensados especialmente para adaptarse a lo que mejor te conviene, tanto en servicios como en presupuesto.
👉 Plan Mensual: Ideal para quienes buscan flexibilidad y compromiso a corto plazo. ¡Solo 12€ al mes! Haz clic aquí para más información
👉 Plan Trimestral Equilibrio perfecto entre compromiso y comodidad. 36€ cada tres meses. Descubre más aquí
👉 Plan Semestral: Únete a nosotros por seis meses a un precio especial de 73€. Infórmate más aquí
En HiveAgile, tu éxito es nuestra prioridad. Te ofrecemos la libertad de elegir cómo y cuándo invertir en tu crecimiento digital. ¡Es tu momento de destacar en el mundo digital con HiveAgile!
🌟 HiveAgile: Adaptándonos a ti, impulsando tu negocio.
Hola,
Hoy hablaremos de la trampa silenciosa de automatizar con LLMs: ese momento cuando llega una factura de 340€ por procesar apenas 500 emails. Te voy a contar un caso real de cómo solucionamos esto y las herramientas que necesitas para que tu próxima automatización sea rentable desde el primer día, no cuando ya tengas problemas de costes.
Llevo una semana un poco liada con todo el tema de lo de la boda, pero espero que está newsletter os guste tanto como a mi escribirla, si te ha gustado marcame con el pulgar y deja algún comentario ;)
G33K TEAM de la Semana
Te dejo por aquí el último episodio de G33K Team.
En el episodio 12, Néstor y Tete desde A Coruña junto con Oriol (¡y con invitado sorpresa incluido!) comentan las últimas novedades de OpenAI con soporte para MCPs vía API, y te muestran Context7 en acción: más de 14.000 librerías indexadas para potenciar tus LLMs con documentación actualizada.
Tete nos presenta Alias Robotics/kai, una herramienta española para hacking ético que está arrasando en plataformas como Hack the Box, mientras que Oriol comparte su experiencia real con NetXMS para descubrimiento automático de infraestructura de red (¡con capturas de pantalla incluidas!).
Además, se meten de lleno en el fascinante mundo de Helium Network y el universo DePIN: desde su evolución de blockchain IoT hasta convertirse en operador 5G real con inversión de 200 millones de Vodafone y Verizon.
PD: Aitor no pudo acompañarnos esta semana porque está ultimando los preparativos de su boda. ¡Le deseamos lo mejor en esta nueva etapa!
¿Es el futuro de la infraestructura descentralizada o una burbuja más? ¡Dale al play y lo descubrimos!
Comparte esta newsletter
¿Te gusta nuestra newsletter sobre #NoCode y #OpenSource? Si quieres que sigamos ofreciendo contenidos accionables y de valor, ¡apóyanos! Una simple acción puede hacer una gran diferencia. Haz clic en el botón abajo y twittea para ayudarnos a crecer. 🚀
ℍ𝕠𝕣𝕚𝕫𝕠𝕟𝕥𝕖 𝔸𝕣𝕥𝕚𝕗𝕚𝕔𝕚𝕒𝕝
Te presentamos "Horizonte Artificial", la nueva y flamante sección de nuestra newsletter dedicada exclusivamente a la Inteligencia Artificial. Pero no esperes el contenido convencional que inunda TikTok o YouTube. Aquí, nos sumergiremos en el fascinante mundo del OpenSource, explorando proyectos libres que puedes desplegar en tu propio servidor. Y para guiarnos en esta travesía, contamos con la experticia de Jesús Pacheco, mejor conocido en nuestra comunidad HiveAgile como "Pachecodes". Prepárate para una perspectiva fresca y auténtica sobre la IA. ¡Bienvenidos al horizonte!
El Coste Real de Automatizar: Cómo Calcular el Precio de un Workflow con APIs de Terceros
Hace unos meses, un cliente me contactó con una mezcla de euforia y pánico. Había automatizado con éxito el análisis de feedback de sus usuarios: emails entrantes, extracción de texto, análisis de sentimiento con OpenAI, resultados a Airtable y notificación por Slack. Una maravilla tecnológica.
Todo era perfecto… hasta que llegó la factura de OpenAI: 340€ en un solo mes. ¿La causa? Procesar apenas 500 emails. El workflow funcionaba, sí, pero el coste se había disparado sin control ni aviso.
Y es que, en el apasionante mundo de la automatización con LLMs, lo que no se mide, se descontrola (y duele en el bolsillo).
La Trampa Silenciosa: Automatizar sin Contar los Céntimos
Es fácil dejarse llevar por la emoción de ver un sistema autónomo funcionando con APIs de terceros. Configuramos el prompt, conectamos los servicios y ¡magia! Pero cada llamada, cada token, tiene un precio. Y muchos lo olvidan en la fase de desarrollo.
He visto casos que te harían sudar frío:
- Bots de atención al cliente cuyas interacciones a 0,02€ acababan sumando 1.200€ mensuales
- Automatizaciones que procesaban el mismo dato una y otra vez por no tener un sistema de caché
- Workflows que, al no distinguir entre clientes o proyectos, hacían imposible saber dónde se estaba quemando el presupuesto
Por eso, la regla de oro es: antes de escalar tu automatización, necesitas controlar el gasto desde el primer token.
Tu Aliado en el Control de Costes: LiteLLM
Aquí es donde entra en juego LiteLLM. Imagina un guardián inteligente que se interpone entre tu aplicación (o tu sistema de automatización como n8n) y los proveedores de modelos de lenguaje como OpenAI, Anthropic, Cohere, Azure, VertexAI, etc.
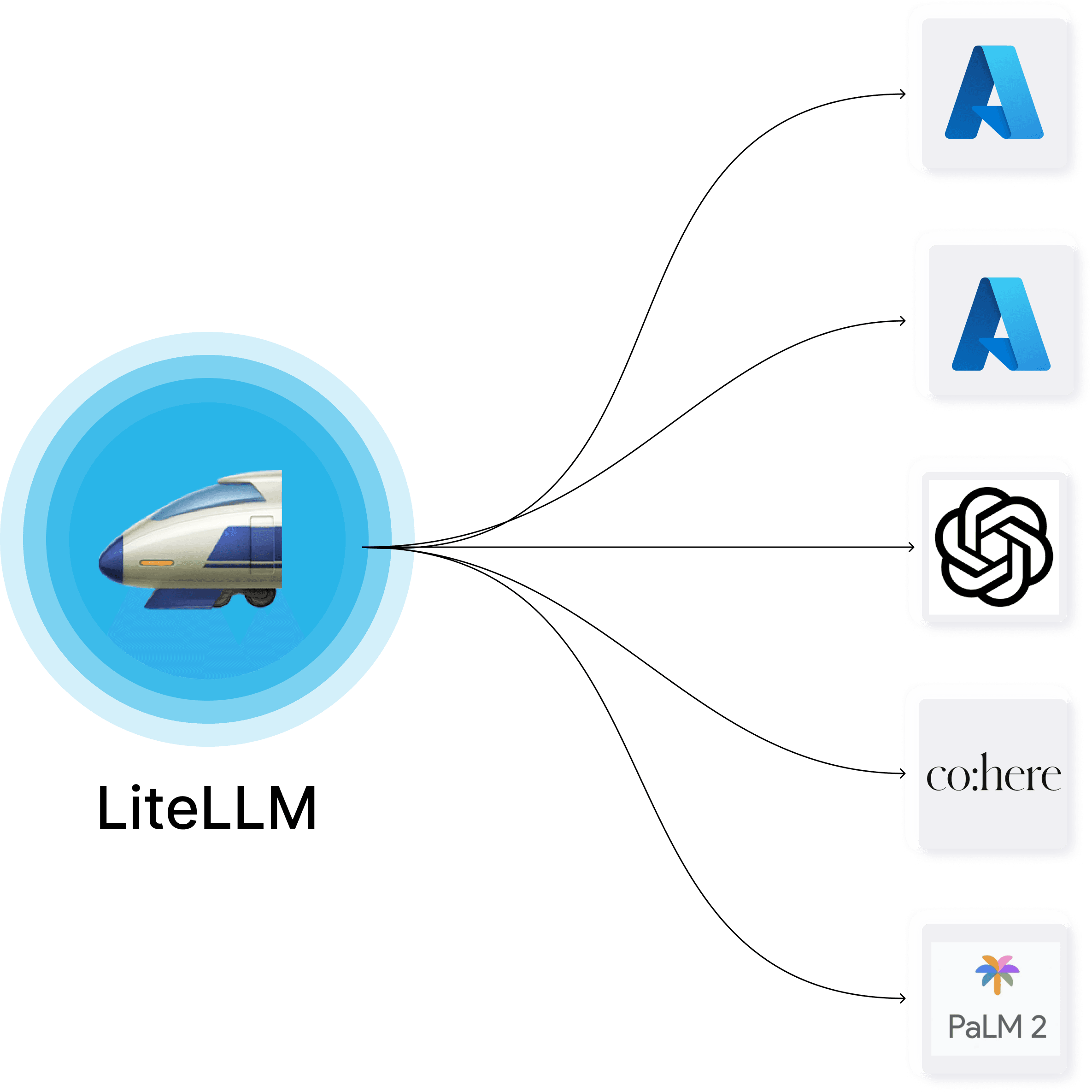
LiteLLM automáticamente rastrea el gasto para todos los modelos conocidos y actúa como un proxy que te da superpoderes para:
- Medir el coste real de cada interacción (en tokens y en dinero)
- Usar Claves Virtuales (Virtual Keys) para asignar presupuestos y permisos específicos a cada cliente, proyecto o incluso a cada workflow
- Etiquetar cada llamada con Tags para un seguimiento granular: por campaña, tipo de usuario, funcionalidad...
- Acceder a un Dashboard Visual para ver el consumo en tiempo real y tomar decisiones informadas
Claves Virtuales: Presupuestos Blindados por Proyecto
LiteLLM permite rastrear gastos y controlar el acceso a modelos a través de claves virtuales para el proxy. Con las Virtual Keys, puedes crear "sub-claves" de tu API key principal. A cada una le asignas:
- Un presupuesto máximo (ej: 100€ al mes)
- Los modelos que puede usar (ej: solo
gpt-3.5-turbopara este cliente) - Metadatos y tags para identificar su origen
Ahora, ACME Corp usará su propia clave virtual. El gasto se rastrea automáticamente para la key en la tabla "LiteLLM_VerificationTokenTable", y si se pasan del presupuesto, LiteLLM bloquea las llamadas, ¡no tu cuenta principal!
Gestión desde la Interfaz Gráfica
Una vez que tienes LiteLLM funcionando, accede a http://localhost:4000/ui y tendrás un dashboard completo donde puedes:
Crear Virtual Keys Visualmente:
- Ve a la sección "Keys" > "Generate New Key"
- Configura nombre, modelos permitidos, presupuesto máximo
- Añade tags y metadata
- El sistema genera automáticamente la key y te muestra el resumen
Dashboard en Tiempo Real: Navega a la pestaña de Uso en la UI de LiteLLM y verifica que veas el gasto rastreado bajo Uso.
Tags: Tu Lupa para el Gasto Detallado
LiteLLM permite pasar tags para rastrear gastos por tags, lo que te permite segmentar y analizar el uso como nunca antes:
- ¿Cuánto costó la campaña de "Black Friday 2024"?
- ¿Qué workflow es el más caro de mantener?
- ¿Qué cliente o departamento genera más gasto por token?
Los Diferentes Modelos de Coste que Te Vas a Encontrar
APIs Basadas en Tokens (OpenAI, Anthropic, Cohere)
LiteLLM utiliza el mapa de costes en vivo de api.litellm.ai para calcular automáticamente los precios por tokens de entrada y salida.
Ejemplo real: GPT-4 Turbo cuesta 0,01$ por 1K tokens de input y 0,03$ por 1K tokens de output. Si tu prompt típico tiene 200 tokens y la respuesta 150 tokens, cada llamada te cuesta aproximadamente 0,0065$.
APIs por Request (Google Maps, Weather APIs)
Cobran por cada llamada, independientemente del volumen de datos.
APIs de Suscripción con Límites (Airtable, Zapier)
Pagas una cuota fija pero tienes límites de uso. Pasarte del límite puede ser muy caro.
Precios Personalizados
Puedes sobrescribir el mapa de costes de modelo con tus propios precios personalizados:
model_list:
- model_name: "gpt-4-custom"
litellm_params:
model: "openai/gpt-4"
api_key: os.environ/OPENAI_API_KEY
model_info:
input_cost_per_token: 0.000025 # Tu precio negociado
output_cost_per_token: 0.000075
Caso Real: De 340€ a 15€ Mensuales
Volvamos a mi cliente. Esto fue lo que hicimos:
Antes:
- Cada email se enviaba directamente a la API de OpenAI (usando el costoso GPT-4 por defecto para una tarea simple)
- Sin tracking de tokens, sin límites, sin visibilidad
- Todo cargado a una única API Key principal
Después con LiteLLM:
1. Configuración del Proxy
Lo primero fue instalar LiteLLM y configurarlo como intermediario entre n8n y OpenAI. En lugar de que el workflow conectase directamente con OpenAI, ahora todas las llamadas pasaban por LiteLLM. Esto nos dio inmediatamente visibilidad total de cada token gastado.
2. Virtual Key con Límite
Creamos una clave virtual específica para este workflow con un presupuesto máximo de 20€ mensuales. Si el gasto se acercaba al límite, LiteLLM enviaría alertas automáticas, y si lo superaba, bloquearía las llamadas para evitar sorpresas.
3. Integración Optimizada en n8n
Modificamos el workflow de n8n para que apuntase al servidor de LiteLLM en lugar de directamente a OpenAI. Cada respuesta ahora incluía el coste exacto de la llamada, permitiendo un seguimiento preciso del gasto por email procesado.
4. Optimizaciones Implementadas
Modelo Adecuado: Cambiamos de GPT-4 a GPT-3.5-turbo. Para análisis de sentimiento básico, GPT-3.5 es más que suficiente y cuesta 20 veces menos. Esta única decisión redujo el 80% del gasto.
Prompts Optimizados: El prompt original incluía ejemplos extensos y contexto innecesario que ocupaba 1.200 tokens. Lo redujimos a un prompt directo de 15 tokens: "Analiza el sentimiento: positivo, negativo o neutral."
Filtrado Inteligente: Añadimos un paso previo en n8n que descarta automáticamente emails de spam, respuestas automáticas (como "noreply") y emails muy cortos que no aportan valor al análisis.
Límite de Respuesta: Configuramos max_tokens a 10 en lugar de dejar que el modelo genere respuestas largas innecesarias.
Resultado: El mismo workflow procesando los mismos emails, pero con un coste de 15€ mensuales en lugar de 340€. Una reducción del 95% manteniendo la misma calidad de resultados.
La clave fue que LiteLLM nos permitió ver exactamente dónde se iba cada céntimo y optimizar cada aspecto del proceso con datos reales, no estimaciones.
Resultado: Mismo workflow, mismos resultados de negocio… pero un coste final de 15€ al mes, totalmente controlado y predecible.
Herramientas para Medir y Estimar Costes
1. Dashboard de LiteLLM
La interfaz gráfica te da métricas en tiempo real:
- Costes por cliente, proyecto o tag
- Gráficos de tendencias de uso
- Alertas automáticas de presupuesto
- Exportación de reportes para facturación
2. APIs de Reporting
Este panel esta recien instalado pero podéis ver que tiene reporte bastante detallado tambien a nivel de modelos y lo mejor de todo es que puedes ver todos los modelos en un mismo lugar.
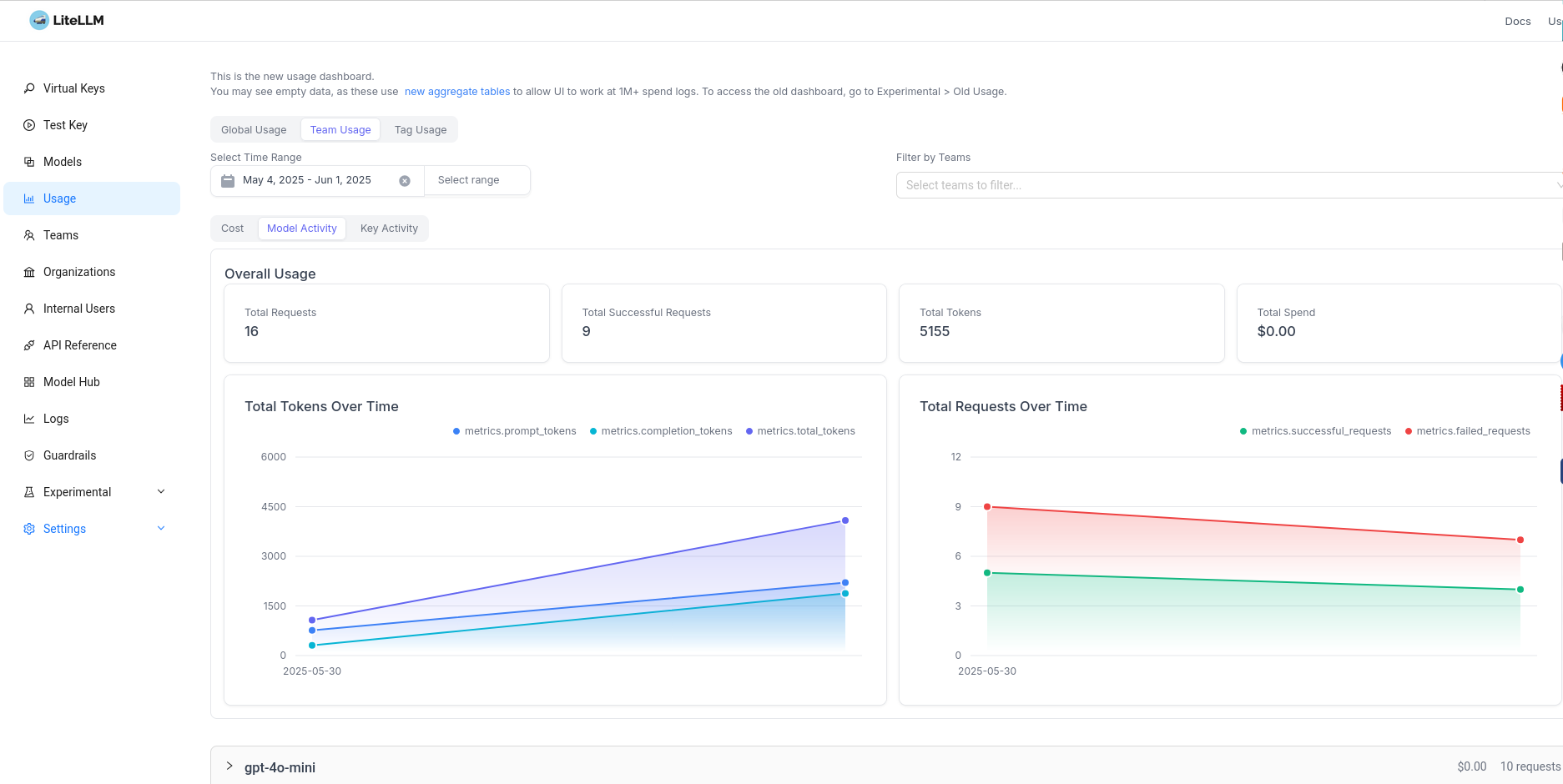
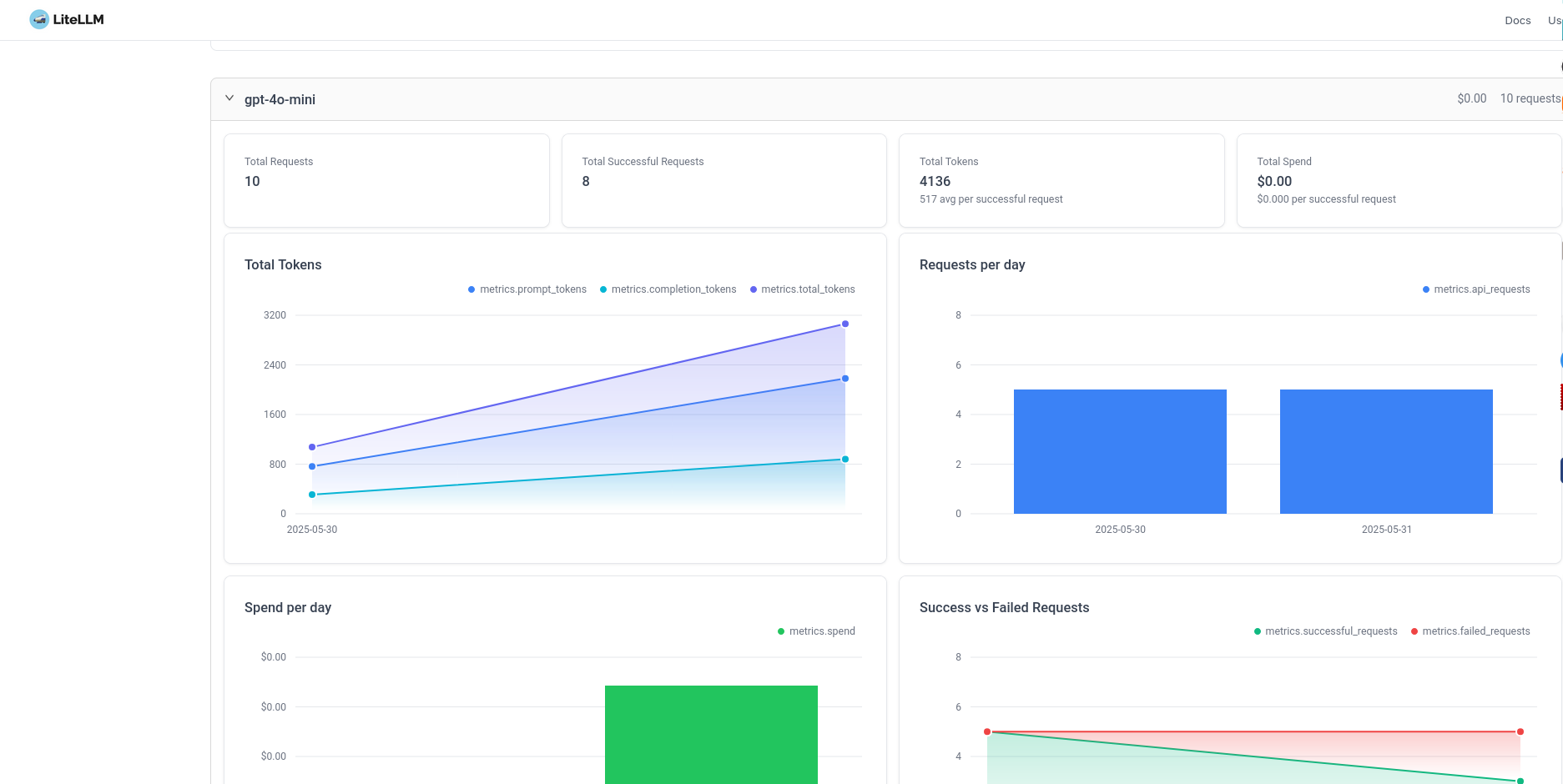
Estrategias para Optimizar Costes
1. Circuit Breakers Automáticos
LiteLLM te permite configurar límites automáticos que se aplican en tiempo real. Puedes establecer presupuestos máximos por día, semana o mes para cada Virtual Key. Cuando se alcanza el límite, el sistema bloquea automáticamente nuevas llamadas, protegiendo tu presupuesto de gastos inesperados.
Por ejemplo, puedes crear una clave con un límite estricto de 10€ diarios. Si tu workflow se dispara por algún error o un bucle infinito, LiteLLM cortará las llamadas antes de que el daño sea mayor.
2. Modelos Fallback para Optimización
Esta función te permite configurar una jerarquía de modelos. Si el modelo principal falla o no está disponible, LiteLLM automáticamente redirige la llamada al modelo de respaldo que hayas configurado.
Además de mejorar la fiabilidad, puedes usar esta función estratégicamente para optimizar costes. Configuras el modelo más caro (como GPT-4) como principal, pero si hay alta demanda o quieres reducir costes, el sistema puede automáticamente usar modelos más baratos (como GPT-3.5-turbo) como fallback o incluso usarlo para evitar caídas si hay indisponibilidad en OpenAI como algunas de las caídas que ha tenido.
3. Caching Inteligente
El caching te permite evitar procesar el mismo contenido múltiples veces. El sistema genera un hash único para cada texto de entrada y guarda el resultado. Si el mismo texto aparece de nuevo, devuelve el resultado guardado sin hacer una nueva llamada costosa a la API.
Esto es especialmente útil en workflows que procesan emails en cadena (donde el mismo contenido se repite) o sistemas que analizan contenido similar repetidamente. Puedes ahorrar hasta un 40% en costes si tienes contenido duplicado frecuente.
La implementación es transparente - tu workflow funciona igual, pero internamente LiteLLM verifica si ya procesó ese contenido antes de hacer la llamada real.
Calculadora de Costes Práctica
Con LiteLLM, calcular costes es mucho más sencillo, ya que obtienes el precio exacto de cada llamada.
Además, puedes consultar los precios actualizados de todos los modelos directamente desde su web.
Lo mejor de todo es que te permite calcular el coste de uso en un único lugar de forma unificada, independientemente del proveedor o modelo que utilices. Ya sean modelos de OpenAI, Anthropic, Mistral u otros, todo queda reflejado en la misma interfaz, lo que facilita enormemente la planificación y control del gasto en tus aplicaciones con IA.
Tu Checklist para Automatizar sin Arruinarte
- Instala LiteLLM y configúralo como proxy para tus modelos
- Crea Virtual Keys para cada cliente, proyecto o entorno
- Define límites de presupuesto realistas para cada Virtual Key
- Usa Tags sistemáticamente para poder analizar el gasto con detalle
- Conecta tus aplicaciones (n8n/Make) a través de LiteLLM
- Monitorea el Dashboard de LiteLLM regularmente
- Optimiza: Revisa prompts, elige el modelo más eficiente para cada tarea y filtra datos innecesarios
LiteLLM no es solo una herramienta técnica; es tu sistema nervioso financiero para tus automatizaciones con IA. Te da el control, la visibilidad y la tranquilidad para innovar y escalar sin el temor constante a una factura desorbitada.
Mi cliente del principio ahora tiene un control total de sus costes usando LiteLLM:
El cambio clave: En lugar de conectar n8n directamente a OpenAI, ahora todo pasa por LiteLLM. Esto le dio:
- Tracking automático de todos los costes
- Virtual Keys para separar clientes
- Tags para análisis granular
- Límites automáticos para evitar sorpresas
- Dashboard visual para monitorizar en tiempo real
La lección es clara: LiteLLM no es solo un proxy, es tu centro de control para automatizaciones rentables. Úsalo desde el primer día, no cuando ya tengas problemas de costes.
Automatizar con LLMs debe ser una fuente de eficiencia y crecimiento, no de estrés financiero. Y LiteLLM te asegura exactamente eso.
¿Tienes algún workflow que se te esté yendo de las manos o quieres empezar tu próximo proyecto de automatización con buen pie? Cuéntamelo en los comentarios y podemos analizarlo juntos.
🌟 TopGit - Resumen Semanal (2025-05-31)
📚 Repositorios Destacados de la Semana
Los siguientes repositorios han sido seleccionados por su relevancia, calidad y métricas de GitHub:
🔧 ⚡ VoltAgent - Framework de Agentes AI
VoltAgent es un marco de trabajo de código abierto en TypeScript para la creación y orquestación de agentes AI. Facilita el desarrollo de aplicaciones impulsadas por agentes autónomos mediante bloques modulares, patrones estandarizados y abstracciones. Ideal para crear chatbots, asistentes virtuales y sistemas complejos de múltiples agentes, VoltAgent se encarga de la complejidad subyacente, permitiendo a los desarrolladores enfocarse en la lógica de los agentes.
📊 Estadísticas de GitHub:
- ⭐ 1,837 estrellas
- 🔄 148 forks
- 👀 12 observadores
- 📝 29 issues abiertos
- 🔤 Principal lenguaje: TypeScript
🔧 🧠 Colección de Workflows de n8n
Esta colección contiene workflows de n8n recopilados de múltiples fuentes, incluyendo exportaciones del sitio web y foros de la comunidad. Su propósito es proporcionar un recurso útil para inspiración, aprendizaje y reutilización en proyectos propios de n8n.
- Descripción: Recurso que agrupa workflows de n8n para facilitar su uso y aprendizaje.
- Características: Archivos .json con workflows nombrados descriptivamente, incluyendo conversiones desde .txt.
- Beneficios: Permite la reutilización de workflows probados y facilita la integración en proyectos personales.
- Casos de uso: Importar workflows a su instancia de n8n, contribuir con nuevos workflows a la colección.
📊 Estadísticas de GitHub:
- ⭐ 1,894 estrellas
- 🔄 514 forks
- 👀 33 observadores
- 📝 3 issues abiertos
- 🔤 Principal lenguaje: No especificado
🔧 🚀 Motor Admin: Panel de Administración Sin Código
Motor Admin permite desplegar un panel de administración sin código para cualquier aplicación en menos de un minuto. Este sistema facilita la búsqueda, creación, actualización y eliminación de entradas de datos, así como la creación de acciones personalizadas y la generación de informes.
📊 Estadísticas de GitHub:
- ⭐ 2,118 estrellas
- 🔄 171 forks
- 👀 19 observadores
- 📝 21 issues abiertos
- 🔤 Principal lenguaje: Ruby
🔧 ⚡️ Flexprice: Medición y facturación basada en el uso
Flexprice es una solución diseñada para desarrolladores que permite implementar modelos de precios flexibles basados en el uso, créditos o híbridos. Automatiza el proceso de medición, tarificación y facturación, permitiendo a los desarrolladores enfocarse en su producto, no en la facturación. Con su arquitectura abierta y su diseño API, facilita la integración con otros servicios existentes como Stripe o Chargebee. Además, proporciona informes claros y precisos sobre el uso y las facturas, asegurando transparencia en los costos.
📊 Estadísticas de GitHub:
- ⭐ 234 estrellas
- 🔄 11 forks
- 👀 3 observadores
- 📝 23 issues abiertos
- 🔤 Principal lenguaje: Go
🔧 🧠 Plantillas para Alchemyst AI
Una colección de plantillas utilizando la plataforma Alchemyst AI para desarrollar tu próxima gran aplicación de inteligencia artificial. Este repositorio incluye recursos que ayudan a los desarrolladores a implementar fácilmente soluciones AI mediante plantillas listas para usar. Su objetivo es facilitar el proceso de creación de aplicaciones, permitiendo a los diseñadores centrarse en la funcionalidad y el diseño sin tener que comenzar desde cero.
📊 Estadísticas de GitHub:
- ⭐ 236 estrellas
- 🔄 0 forks
- 👀 1 observadores
- 📝 0 issues abiertos
- 🔤 Principal lenguaje: JavaScript
📊 Análisis de Distribución por Categorías
La siguiente gráfica muestra la distribución de proyectos por categoría en TopGit:
📈 Estadísticas Semanales
🏆 Top 3 Categorías
📊 Distribución Detallada
🔧 Dev ████████ 40% (2 repos)
🤖 IA & Machine Learning ████████ 40% (2 repos)
🌐 Web Development ████ 20% (1 repos)
🚀 Tendencias Destacadas
📈 Métricas Clave
- Repositorios Totales: 5
- Promedio Diario: 0.7 repos/día
- Categorías Activas: 3
🎯 Categorías Dominantes
- Dev
- 2 repositorios
- 40.0% del total
- IA & Machine Learning
- 2 repositorios
- 40.0% del total
- Web Development
- 1 repositorios
- 20.0% del total
💡 Análisis de Tendencias
Basándonos en las tendencias observadas en GitHub durante la semana que concluye el 31 de mayo de 2025, se destacan cinco proyectos principales:
- VoltAgent, un marco de trabajo en TypeScript para la creación y coordinación de agentes IA. Este marco simplifica el proceso de creación de aplicaciones orientadas a agentes autónomos como chatbots o asistentes virtuales. Se encuentra al frente de la lista y es de particular relevancia debido al creciente interés en la inteligencia artificial y automatización.
- La Colección de Workflows de n8n se presenta como una herramienta valiosa para aquellos interesados en el uso y aprendizaje de n8n. Este repositorio agrega workflows de diversas fuentes y puede ser una excelente herramienta para acelerar el desarrollo de proyectos en n8n.
- Motor Admin es un proyecto destinado a facilitar la administración de aplicaciones. Permite desplegar un panel de administración completo sin escribir una sola línea de código. Siendo el tercero en la lista, esta herramienta es particularmente atractiva para desarrolladores que requieran implementar fácilmente funcionalidades backend.
- Flexprice permite a los desarrolladores agregar facturación basada en el uso a sus propias aplicaciones. Este proyecto maneja automáticamente el monitoreo, tarificación y facturación, permitiendo a los desarrolladores centrarse en su producto. En un mundo cada vez más orientado a los servicios, Flexprice podría ser un recurso valioso para muchos desarrolladores.
- Las Plantillas para Alchemyst AI ofrecen una valiosa colección de plantillas para el desarrollo de aplicaciones de inteligencia artificial. En línea con la tendencia actual hacia la IA, este conjunto de plantillas puede facilitar significativamente el proceso de desarrollo de nuevas soluciones basadas en tecnologías de inteligencia artificial.
Estas tendencias reflejan el creciente interés en la automatización, la inteligencia artificial, la simplificación de procesos de desarrollo y administración y el auge de la economía de servicios individuales y flexibles. Estos repositorios son una excelente indicación de hacia dónde se dirige el mundo del desarrollo tecnológico.
- 🐥 Únete a nuestra vibrante comunidad en Twitter y mantente en la vanguardia: descubre herramientas innovadoras, participa en nuestro emocionante #BuildInPublic y mucho más.
- 💌 ¿Tienes algo que compartir? No dudes en contactarnos. Tu voz es importante para nosotros y nos comprometemos a responder a la mayor brevedad posible.¡házmelo saber!

Soy Jesús Pacheco, y cada domingo te cuento qué está pasando en el mundo de la inteligencia artificial sin el ruido de siempre.
Esta semana han salido tres herramientas que me han llamado la atención, y creo que a ti también te van a interesar.
La herramienta que me hizo editar 50 fotos en una tarde
FLUX.1 Kontext llegó la semana pasada y, honestamente, pensé que sería otra herramienta más de edición con IA. Me equivoqué.
El fin de semana tenía que preparar imágenes para el blog de mi hermana (tiene una tienda de cerámica artesanal). Normalmente me toma horas en Photoshop cambiar fondos, ajustar colores, ese tipo de cosas. Con FLUX.1 Kontext tardé literalmente una tarde.
Lo que me gustó de verdad:
Es preciso. Le dices "cambia el fondo por uno minimalista blanco" y lo hace. Sin rarezas, sin colores extraños que aparecen de la nada.
Entiende el contexto. Cuando le pedí "haz que la cerámica se vea más artesanal pero mantén los colores originales", entendió perfectamente qué quería.
No es caro. Comparado con lo que cuesta un editor freelance, es ridículamente económico.
Leer la historia completa
Registrarse ahora para leer la historia completa y obtener acceso a todos los puestos para sólo suscriptores de pago.
Suscribirse